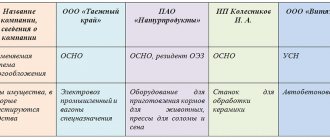
Для чего нужна справка 2-НДФЛ с предыдущего места работы?
Автор вопроса: Евсеев Д. Создано: 21.02.22
Справка 2-НДФЛ при приеме на работу. При трудоустройстве работодатель вправе потребовать принести справку по форме 2-НДФЛ с прошлого места работы (утв. приказом ФНС от 02.10.2018 № ММВ-7-11/566). Справка нужна для того, чтобы представить стандартные вычеты сотрудникам с детьми. Дело в том, что сотрудник вправе на вычет только если его доход за год не превышает 350 000 руб. Эту сумму считают нарастающим итогом с начала года (п. 1 ст. 218 НК РФ). Данные о доходах за текущий год записаны в справке 2-НДФЛ, которую прошлый работодател
Ответил(а): Овчинников Д. 22.02.22
Что такое нарастающий итог при расчете налога на прибыль?
Налоговой базой по налогу на прибыль является денежное выражение прибыли организации (п. 1 ст. 274 НК РФ).
При определении налоговой базы облагаемая прибыль определяется нарастающим итогом с начала налогового периода (п. 7 ст. 274 НК РФ). Исходя из базы за год исчисляется налог.
Авансы по итогам отчетных периодов исчисляются исходя из прибыли, рассчитанной нарастающим итогом с начала налогового периода до окончания отчетного периода (п. 2 ст. 286 НК РФ). Нарастающий итог означает, что прибыль отчетного квартала определяется исходя из доходов и расходов, полученных/понесенных с начала года до отчетной даты. То есть она фактически включает в себя и прибыль/убыток прошлого отчетного периода, и прибыль/убыток текущего.
Как правильно считать авансовые платежи по налогу на прибыль, узнайте в КонсультантПлюс. Если у вас нет доступа к системе, получите пробный онлайн-доступ бесплатно.
Про нарастающий итог в другом отчете читайте в материале «6-НДФЛ заполняется нарастающим итогом с начала года».
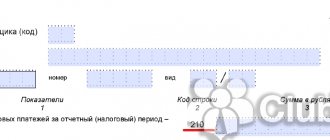
Как заполнить строку 140 в 6 НДФЛ?
Автор вопроса: Макаров Е. Создано: 20.02.22
Как заполнить строку 140
в расчете
6
—
НДФЛ
по новой форме В поле
140
(ранее
строка
040) «Сумма налога исчисленная» отразите сумму исчисленного налога по ставке из поля 100 нарастающим итогом с начала года. Чтобы определить величину этого показателя, сложите суммы
НДФЛ
, начисленные с доходов всех сотрудников.
Ответил(а): Сидорова В. 23.02.22
Нарастающий итог в SQL
Нарастающий (накопительный) итог долго считался одним из вызовов SQL. Что удивительно, даже после появления оконных функций он продолжает быть пугалом (во всяком случае, для новичков). Сегодня мы рассмотрим механику 10 самых интересных решений этой задачи – от оконных функций до весьма специфических хаков. В электронных таблицах вроде Excel нарастающий итог вычисляется очень просто: результат в первой записи совпадает с её значением:
… а затем мы суммируем текущее значение и предыдущий итог.
Иными словами,
… или:
Появление в таблице двух и более групп несколько усложняет задачу: теперь мы считаем несколько итогов (для каждой группы отдельно). Впрочем, и здесь решение лежит на поверхности: необходимо каждый раз проверять, к какой группе принадлежит текущая запись. Click and drag
, и работа выполнена:
Как можно заметить, подсчёт нарастающего итога связан с двумя неизменными составляющими: (а)
сортировкой данных по дате и
(б)
обращением к предыдущей строке.
Но что SQL? Очень долго в нём не было нужного функционала. Необходимый инструмент – оконные функции – впервые появился только стандарте SQL:2003
. К этому моменту они уже были в Oracle (версия 8i). А вот реализация в других СУБД задержалась на 5-10 лет: SQL Server 2012, MySQL 8.0.2 (2018 год), MariaDB 10.2.0 (2017 год), PostgreSQL 8.4 (2009 год), DB2 9 для z/OS (2007 год), и даже SQLite 3.25 (2018 год).
Тестовые данные
— создание таблиц и наполнение их данными — — простейший случай create table test_simple (dt date NULL, val int NULL ); — используем формат дат своей СУБД (или меняем настройки, напр. через NLS_DATE_FORMAT в Oracle) insert into test_simple (dt, val) values (‘2019-11-01’, 6); insert into test_simple (dt, val) values (‘2019-11-02’, 3); insert into test_simple (dt, val) values (‘2019-11-03’, 3); insert into test_simple (dt, val) values (‘2019-11-04’, 4); insert into test_simple (dt, val) values (‘2019-11-05’, 2); insert into test_simple (dt, val) values (‘2019-11-06’, 4); insert into test_simple (dt, val) values (‘2019-11-07’, 8); insert into test_simple (dt, val) values (‘2019-11-08’, 0); insert into test_simple (dt, val) values (‘2019-11-09’, 6); insert into test_simple (dt, val) values (‘2019-11-10’, 0); insert into test_simple (dt, val) values (‘2019-11-11’, 8); insert into test_simple (dt, val) values (‘2019-11-12’, 8); insert into test_simple (dt, val) values (‘2019-11-13’, 0); insert into test_simple (dt, val) values (‘2019-11-14’, 2); insert into test_simple (dt, val) values (‘2019-11-15’, 8); insert into test_simple (dt, val) values (‘2019-11-16’, 7); — случай с группами create table test_groups (grp varchar NULL, — varchar2(1) in Oracle dt date NULL, val int NULL ); — используем формат дат своей СУБД (или меняем настройки, напр. через NLS_DATE_FORMAT в Oracle) insert into test_groups (grp, dt, val) values (‘a’, ‘2019-11-06’, 1); insert into test_groups (grp, dt, val) values (‘a’, ‘2019-11-07’, 3); insert into test_groups (grp, dt, val) values (‘a’, ‘2019-11-08’, 4); insert into test_groups (grp, dt, val) values (‘a’, ‘2019-11-09’, 1); insert into test_groups (grp, dt, val) values (‘a’, ‘2019-11-10’, 7); insert into test_groups (grp, dt, val) values (‘b’, ‘2019-11-06’, 9); insert into test_groups (grp, dt, val) values (‘b’, ‘2019-11-07’, 10); insert into test_groups (grp, dt, val) values (‘b’, ‘2019-11-08’, 9); insert into test_groups (grp, dt, val) values (‘b’, ‘2019-11-09’, 1); insert into test_groups (grp, dt, val) values (‘b’, ‘2019-11-10’, 10); insert into test_groups (grp, dt, val) values (‘c’, ‘2019-11-06’, 4); insert into test_groups (grp, dt, val) values (‘c’, ‘2019-11-07’, 10); insert into test_groups (grp, dt, val) values (‘c’, ‘2019-11-08’, 9); insert into test_groups (grp, dt, val) values (‘c’, ‘2019-11-09’, 4); insert into test_groups (grp, dt, val) values (‘c’, ‘2019-11-10’, 4); — проверяем данные — select * from test_simple order by dt; select * from test_groups order by grp, dt;
Оконные функции
Оконные функции – вероятно, самый простой способ. В базовом случае (таблица без групп) мы рассматриваем данные, отсортированные по дате: order by dt … но нас интересуют только строки до текущей: rows between unbounded preceding and current row В конечном итоге, нам нужна сумма с этими параметрами: sum(val) over (order by dt rows between unbounded preceding and current row) А полный запрос будет выглядеть так: select s.*, coalesce(sum(s.val) over (order by s.dt rows between unbounded preceding and current row), 0) as total from test_simple s order by s.dt; В случае нарастающего итога по группам (поле grp) нам требуется только одна небольшая правка. Теперь мы рассматриваем данные как разделённые на «окна» по признаку группы:
Чтобы учесть это разделение необходимо использовать ключевое слово partition by :
partition by grp И, соответственно, считать сумму по этим окнам: sum(val) over (partition by grp order by dt rows between unbounded preceding and current row) Тогда весь запрос преобразуется таким образом: select tg.*, coalesce(sum(tg.val) over (partition by tg.grp order by tg.dt rows between unbounded preceding and current row), 0) as total from test_groups tg order by tg.grp, tg.dt; Производительность оконных функций будет зависеть от специфики вашей СУБД (и её версии!), размеров таблицы, и наличия индексов. Но в большинстве случаев этот метод будет самым эффективным. Тем не менее, оконные функции недоступны в старых версиях СУБД (которые ещё в ходу). Кроме того, их нет в таких СУБД как Microsoft Access и SAP/Sybase ASE. Если необходимо вендоро-независимое решение, следует обратить внимание на альтернативы.
Подзапрос
Как было сказано выше, оконные функции были очень поздно введены в основных СУБД. Эта задержка не должна удивлять: в реляционной теории данные не упорядочены. Куда больше духу реляционной теории соответствует решение через подзапрос.
Такой подзапрос должен считать сумму значений с датой до текущей (и включая текущую): .
Что в коде выглядит так:
select s.*, (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt <= s.dt) as total from test_simple s order by s.dt; Чуть более эффективным будет решение, в котором подзапрос считает итог до текущей даты (но не включая её), а затем суммирует его со значением в строке: select s.*, s.val + (select coalesce(sum(t2.val), 0) from test_simple t2 where t2.dt < s.dt) as total from test_simple s order by s.dt; В случае нарастающего итога по нескольким группам нам необходимо использовать коррелированный подзапрос: select g.*, (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt) as total from test_groups g order by g.grp, g.dt; Условие g.grp = t2.grp проверяет строки на вхождение в группу (что, в принципе, сходно с работой partition by grp в оконных функциях).
Внутреннее соединение
Поскольку подзапросы и джойны взаимозаменяемы, мы легко можем заменить одно на другое. Для этого необходимо использовать Self Join, соединив два экземпляра одной и той же таблицы: select s.*, coalesce(sum(t2.val), 0) as total from test_simple s inner join test_simple t2 on t2.dt <= s.dt group by s.dt, s.val order by s.dt; Как можно заметить, условие фильтрации в подзапросе t2.dt <= s.dt стало условием соединения. Кроме того, чтобы использовать агрегирующую функцию sum() нам необходима группировка по дате и значению group by s.dt, s.val.
Точно также можно сделать для случая с разными группами grp:
select g.*, coalesce(sum(t2.val), 0) as total from test_groups g inner join test_groups t2 on g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt;
Декартово произведение
Раз уж мы заменили подзапрос на join, то почему бы не попробовать декартово произведение? Это решение потребует только минимальных правок: select s.*, coalesce(sum(t2.val), 0) as total from test_simple s, test_simple t2 where t2.dt <= s.dt group by s.dt, s.val order by s.dt; Или для случая с группами: select g.*, coalesce(sum(t2.val), 0) as total from test_groups g, test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt group by g.grp, g.dt, g.val order by g.grp, g.dt; Перечисленные решения (подзапрос, inner join, cartesian join) соответсвуют SQL-92
и
SQL:1999
, а потому будут доступны практически в любой СУБД. Основная проблема всех этих решений в низкой производительности. Это не велика беда, если мы материализуем таблицу с результатом (но ведь всё равно хочется большей скорости!). Дальнейшие методы куда более эффективны (с поправкой на уже указанные специфику конкретных СУБД и их версий, размер таблицы, индексы).
Рекурсивный запрос
Один из более специфических подходов – это рекурсивный запрос в common table expression. Для этого нам необходим «якорь» – запрос, возвращающий самую первую строку: select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple) Затем к «якорю» с помощью union all присоединяются результаты рекурсивного запроса. Для этого можно опереться на поле даты dt, прибавляя у нему по одному дню: select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt) — + 1 день в SQL Server Часть кода, добавляющая один день, не универсальна. Например, это r.dt = dateadd(day, 1, cte.dt) для SQL Server, r.dt = cte.dt + 1 для Oracle, и т.д.
Совместив «якорь» и основной запрос, мы получим окончательный результат:
with cte (dt, val, total) as (select dt, val, val as total from test_simple where dt = (select min(dt) from test_simple) union all select r.dt, r.val, cte.total + r.val from cte inner join test_simple r on r.dt = dateadd(day, 1, cte.dt) — r.dt = cte.dt + 1 в Oracle, и т.п. ) select dt, val, total from cte order by dt; Решение для случая с группами будет ненамного сложнее: with cte (dt, grp, val, total) as (select g.dt, g.grp, g.val, g.val as total from test_groups g where g.dt = (select min(dt) from test_groups where grp = g.grp) union all select r.dt, r.grp, r.val, cte.total + r.val from cte inner join test_groups r on r.dt = dateadd(day, 1, cte.dt) — r.dt = cte.dt + 1 в Oracle, и т.п. and cte.grp = r.grp ) select dt, grp, val, total from cte order by grp, dt;
Рекурсивный запрос с функцией row_number()
Предыдущее решение опиралось на непрерывность поля даты dt с последовательным приростом на 1 день. Мы избежать этого, используя оконную функцию row_number(), которая нумерует строки. Конечно, это нечестно – ведь мы собрались рассматривать альтернативы оконным функциям. Тем не менее, это решение может быть своего рода proof of concept
: ведь на практике может быть поле, заменяющее номера строк (id записи). Кроме того, в SQL Server функция row_number() появилась раньше, чем была введена полноценная поддержка оконных функций (включая sum()).
Итак, для рекурсивного запроса с row_number() нам понадобится два СТЕ. В первом мы только нумеруем строки:
with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple) … и если номер строки уже есть в таблице, то можно без него обойтись. В следующем запросе обращаемся уже к cte1: cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 ) А целиком запрос выглядит так: with cte1 (dt, val, rn) as (select dt, val, row_number() over (order by dt) as rn from test_simple), cte2 (dt, val, rn, total) as (select dt, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.rn = cte2.rn + 1 ) select dt, val, total from cte2 order by dt; … или для случая с группами: with cte1 (dt, grp, val, rn) as (select dt, grp, val, row_number() over (partition by grp order by dt) as rn from test_groups), cte2 (dt, grp, val, rn, total) as (select dt, grp, val, rn, val as total from cte1 where rn = 1 union all select cte1.dt, cte1.grp, cte1.val, cte1.rn, cte2.total + cte1.val from cte2 inner join cte1 on cte1.grp = cte2.grp and cte1.rn = cte2.rn + 1 ) select dt, grp, val, total from cte2 order by grp, dt;
Оператор CROSS APPLY / LATERAL
Один из самых экзотических способов расчёта нарастающего итога – это использование оператора CROSS APPLY (SQL Server, Oracle) или эквивалентного ему LATERAL (MySQL, PostgreSQL). Эти операторы появились довольно поздно (например, в Oracle только с версии 12c). А в некоторых СУБД (например, MariaDB) их и вовсе нет. Поэтому это решение представляет чисто эстетический интерес.
Функционально использование CROSS APPLY или LATERAL идентично подзапросу: мы присоединяем к основному запросу результат вычисления:
cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2 … что целиком выглядит так: select s.*, t2.total from test_simple s cross apply (select coalesce(sum(t2.val), 0) as total from test_simple t2 where t2.dt <= s.dt ) t2 order by s.dt; Похожим будет и решение для случая с группами: select g.*, t2.total from test_groups g cross apply (select coalesce(sum(t2.val), 0) as total from test_groups t2 where g.grp = t2.grp and t2.dt <= g.dt ) t2 order by g.grp, g.dt; Итого: мы рассмотрели основные платформо-независимые решения. Но остаются решения, специфичные для конкретных СУБД! Поскольку здесь возможно очень много вариантов, остановимся на нескольких наиболее интересных.
Оператор MODEL (Oracle)
Оператор MODEL в Oracle даёт одно из самых элегантных решений. В начале статьи мы рассмотрели общую формулу нарастающего итога:
MODEL позволяет реализовать эту формулу буквально один к одному! Для этого мы сначала заполняем поле total значениями текущей строки
select dt, val, val as total from test_simple … затем рассчитываем номер строки как row_number() over (order by dt) as rn (или используем готовое поле с номером, если оно есть). И, наконец, вводим правило для всех строк, кроме первой: total = total[cv() — 1] + val[cv()].
Функция cv() здесь отвечает за значение текущей строки. А весь запрос будет выглядеть так:
select dt, val, total from (select dt, val, val as total from test_simple) t model dimension by (row_number() over (order by dt) as rn) measures (dt, val, total) rules (total = total[cv() — 1] + val[cv()]) order by dt;
Курсор (SQL Server)
Нарастающий итог – один из немногих случаев, когда курсор в SQL Server не только полезен, но и предпочтителен другим решениям (как минимум до версии 2012, где появились оконные функции).
Реализация через курсор довольно тривиальна. Сначала необходимо создать временную таблицу и заполнить её датами и значениями из основной:
create table #temp (dt date primary key, val int NULL, total int NULL ); insert #temp (dt, val) select dt, val from test_simple order by dt; Затем задаём локальные переменные, через которые будет происходить обновление: declare @VarTotal int, @VarDT date, @VarVal int; set @VarTotal = 0; После этого обновляем временную таблицу через курсор: declare cur cursor local static read_only forward_only for select dt, val from #temp order by dt; open cur; fetch cur into @VarDT, @VarVal; while @@fetch_status = 0 begin set @VarTotal = @VarTotal + @VarVal; update #temp set total = @VarTotal where dt = @VarDT; fetch cur into @VarDT, @VarVal; end; close cur; deallocate cur; И, наконец, получем нужный результат: select dt, val, total from #temp order by dt; drop table #temp;
Обновление через локальную переменную (SQL Server)
Обновление через локальную переменную в SQL Server основано на недокументированном поведении, поэтому его нельзя считать надёжным. Тем не менее, это едва ли не самое быстрое решение, и этим оно интересно.
Создадим две переменные: одну для нарастающих итогов и табличную переменную:
declare @VarTotal int = 0; declare @tv table (dt date NULL, val int NULL, total int NULL ); Сначала заполним @tv данным из основной таблицы insert @tv (dt, val, total) select dt, val, 0 as total from test_simple order by dt; Затем табличную переменную @tv обновим, используя @VarTotal: update @tv set @VarTotal = total = @VarTotal + val from @tv; … после чего получим окончательный результат: select * from @tv order by dt; Резюме: мы рассмотрели топ 10 способов расчёта нарастающего итога в SQL. Как можно заметить, даже без оконных функций эта задача вполне решаема, причём механику решения нельзя назвать сложной.
Как по осв посмотреть прибыль или убыток?
Автор вопроса: Веселов И. Создано: 21.02.22
Для того чтобы посмотреть прибыль, нужно сформировать ОСВ по счету 99.01 за нужный период. Оборот по кредиту счета – это прибыль, полученная в течение периода, оборот по дебету – убыток. Сальдо на конец периода – это полученная по итогам периода прибыль или убыток. Финансовый результат формируется нарастающим итогом с начала года. 31 декабря производится реформация баланса, и накопленный остаток по счету 99.01 списывается на счет 84 (нераспеределенная прибыль/непокрытый убыток).
Ответил(а): Данилова Б. 23.02.22
Внесение авансовых платежей
После подсчета авансовых платежей по показателям прошлых периодов фирма обязана перевести уплату аванса за каждый месяц текущего квартала не позднее 28 числа. Когда заканчивается отчетный период — в нашем случае, квартал — налог считают из фактических показателей доходности. Если после вычета авансов есть недоплата, ее вносят дополнительно.
Ежемесячные авансовые платежи перечисляют до 28 числа следующего за отчетным месяца. До 28 февраля следует заплатить за январь, до 28 марта — за февраль и т.д. Последний платеж за декабрь–январь вносят до 28 марта следующего года.
Ежеквартальные платежи перечисляют до 28 числа месяца после окончания отчетного квартала. Например, за 1 квартал до 28 апреля, 2 и 3 квартал — до 28 июля и октября соответственно. Итоговый платеж за год должен пройти до 28 марта следующего года.
Вновь созданные организации могут платить раз в квартал — по третьей схеме. Фирма считается новой в течении четырех кварталов после ее создания. При условии соблюдении минимального лимита прибыли в 5 млн. руб. в месяц, компания может не вносить ежемесячные авансовые платежи. Второе условие, конкретизированное в ст. 287, п.5 НК РФ для таких организаций — прибыль не больше 15 млн. в квартал.